
Vector Search with Amazon MemoryDB
As applications in AI, machine learning, and real-time analytics grow in complexity, the need for ultra-fast and efficient data storage and retrieval systems becomes critical. Amazon MemoryDB, a fully managed, Redis-compatible, in-memory database, is ideally suited for such needs, especially when it comes to real-time vector search capabilities. In this blog post, we will walk through a practical tutorial on how to implement a real-time vector search using MemoryDB.
Table of Contents
What is Amazon MemoryDB?
Amazon MemoryDB is a managed, Redis-compatible, in-memory database service designed for high performance and low latency. It stores the entire dataset in memory, providing sub-millisecond latency for read and write operations. This makes it an excellent choice for real-time applications that require rapid data access, such as vector search in AI-driven applications.
Understanding Vector Search
Vector search is a method of finding similar items in a dataset by comparing their vector representations. Vectors are arrays of numbers that encode features of items, whether they are images, texts, or other data types. Searching for the nearest vectors—often referred to as nearest neighbor search (NNS)—is a common requirement in recommendation engines, image retrieval, and natural language processing tasks.
Why Use Amazon MemoryDB for Vector Search?
In-Memory Performance: MemoryDB provides extremely low latency by keeping data in memory, which is essential for real-time vector search.
Redis Compatibility: Developers can leverage familiar Redis commands and data structures to manage and query vectors, making integration straightforward.
Scalability: MemoryDB supports both horizontal and vertical scaling to meet changing demands. You can scale out by adding shards or read replicas to distribute the dataset across multiple nodes, improving performance and scalability. MemoryDB also supports online resharding and shard rebalancing, ensuring smooth scaling without downtime.
High Availability: With multi-AZ configurations and automatic failover, MemoryDB ensures high availability and resilience, even in the face of failures.
Monitoring and Management: MemoryDB integrates with Amazon CloudWatch to provide operational and performance metrics, allowing you to monitor your cluster and scale it based on real-time demand.
Tutorial
We’ll walk through the steps to set up a real-time vector search on Amazon-PQA dataset, which includes product questions, answers, and public product information, to perform a search. We’ll use Python for the implementation.
Set up Amazon MemoryDB
Log in to the AWS Management Console. Navigate to the MemoryDB service and create a new cluster. Choose the instance type and number of replicas as per your requirements. Here is a simple setup case:
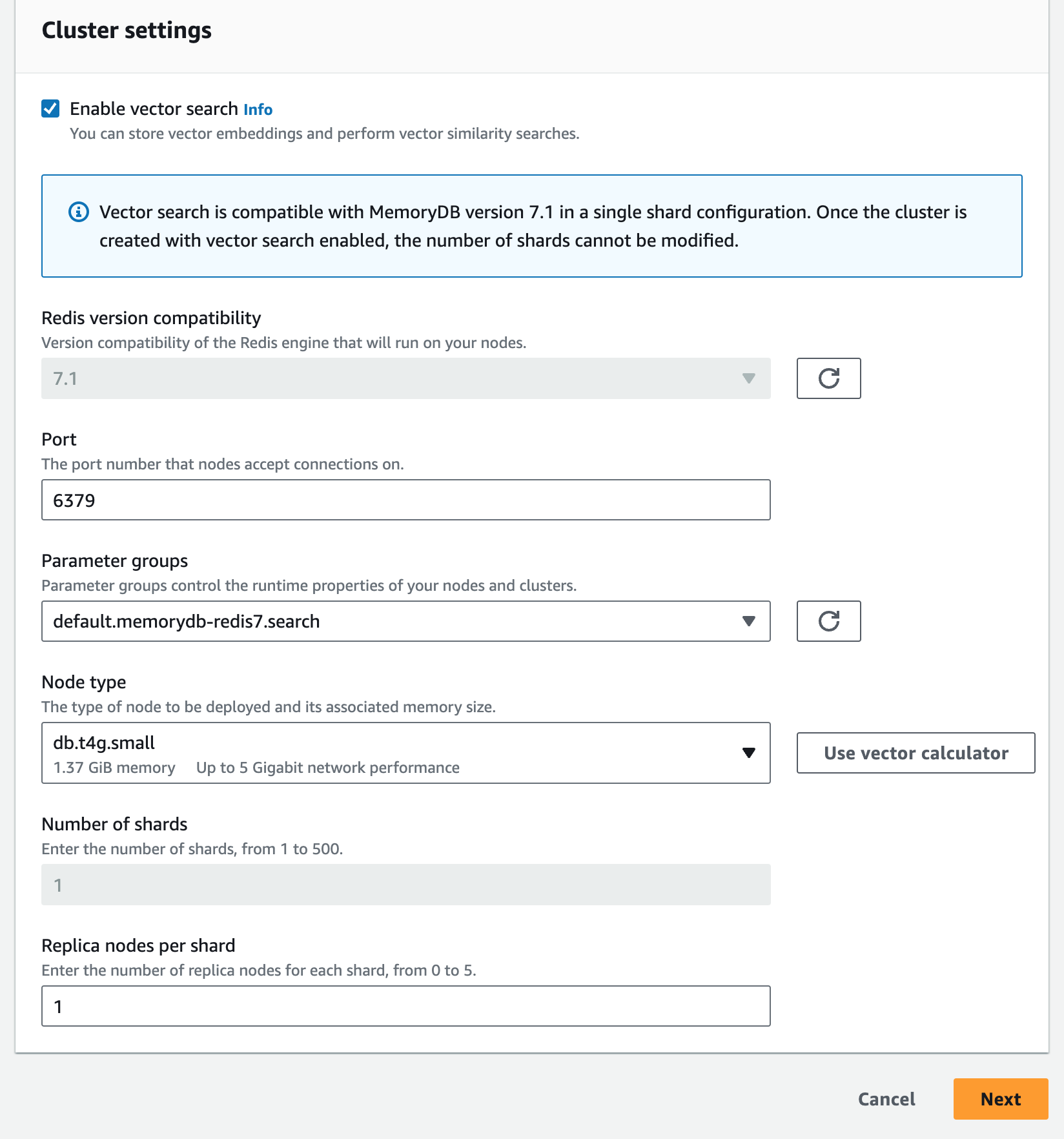
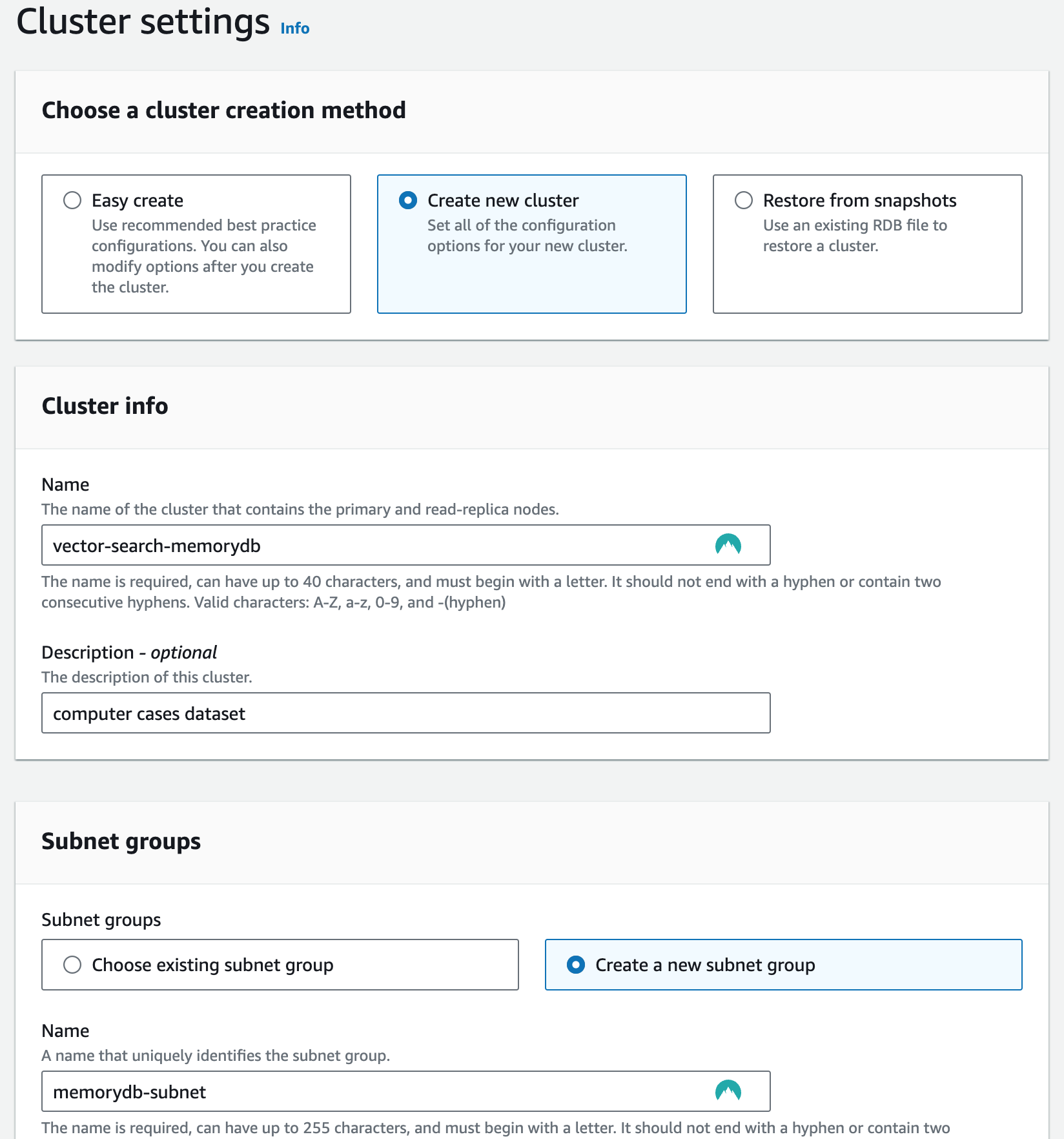 make sure to enable vector search in cluster settings:
make sure to enable vector search in cluster settings:
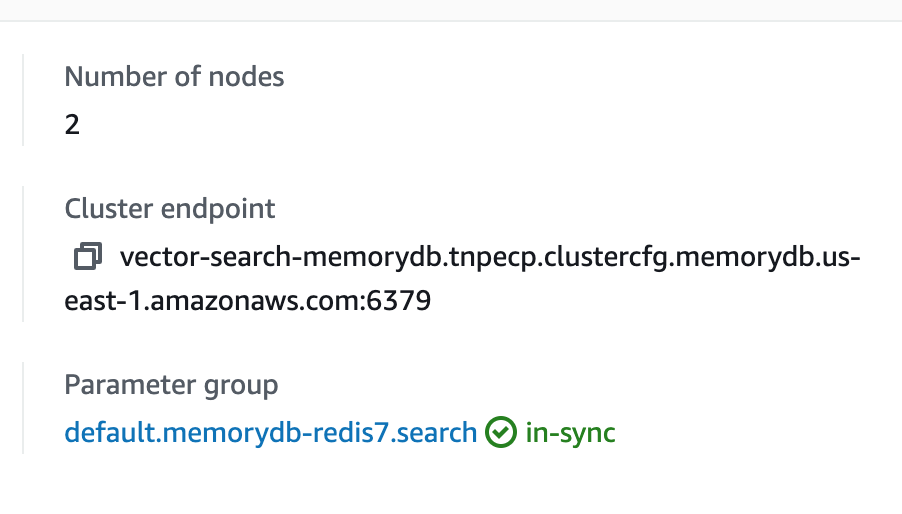
Once the cluster is ready, obtain the endpoint and port number, which will be used to connect to the MemoryDB cluster from your application:
Test connection
from redis.cluster import RedisCluster
try:
redis_client = RedisCluster(host="replace_with_endpoint_name",
port="6379",
decode_responses=True)
if redis_client.ping():
print("Connected to Redis cluster")
except Exception as e:
print(f"Error connecting to Redis cluster: {e}")
You should see output as:
Connected to Redis cluster
Create index and schema in MemoryDB
from redis.commands.search.query import Query
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
# Define the index name
index_name = 'product_index'
# Create the index with the specified schema
redis_client.ft(index_name).create_index([
TextField("question"),
TextField("answer"),
VectorField("question_vector", "HNSW", {
"TYPE": "FLOAT32",
"DIM": 768,
"DISTANCE_METRIC": "COSINE",
"INITIAL_CAP": 1000,
"M": 16
})
], definition=IndexDefinition(prefix=[''], index_type=IndexType.HASH))
Prepare data for loading
For this demo, we’ll use the Amazon QA dataset for computer cases, loading just the first 1000 rows of data. We’ll leverage a pre-trained model (all-distilroberta-v1) to encode each question into a vector, creating a dictionary (vector_dict) that maps each question’s ID to its text, answer, and vector representation. This dictionary will then be used to store the data in a vector search index.
import requests
import json
import numpy as np
from sentence_transformers import SentenceTransformer
# Load the JSON data (only the first 1000 lines)
url = "https://amazon-pqa.s3.amazonaws.com/amazon_pqa_computer_cases.json"
response = requests.get(url)
data = response.text.splitlines()[:1000] # Load only the first 1000 rows
# Load the model
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
# Prepare the vector dictionary for the first 1000 rows
vector_dict = {}
for i, line in enumerate(data):
item = json.loads(line)
question_text = item['question_text']
vector = model.encode(question_text).astype(np.float32).tobytes()
vector_dict[item['question_id']] = {
"question": question_text,
"answer": item['answers'][0]['answer_text'] if item['answers'] else "",
"vector": vector
}
print('data preparation done.')
Load vectors into MemoryDB
def load_vectors(redis_client, vector_dict):
for key, value in vector_dict.items():
redis_client.hset(key, mapping={
"question": value["question"],
"answer": value["answer"],
"question_vector": value["vector"]
})
load_vectors(redis_client, vector_dict)
print("Vectors loaded into MemoryDB.")
Execute search
from redis.commands.search.query import Query
user_query = 'Is there a passive CPU cooler'
query_vector = model.encode(user_query).astype(np.float32).tobytes()
topK = 5
q = Query(f'*=>[KNN {topK} @question_vector $vec_param AS vector_score]').paging(0, topK).return_fields('question', 'answer')
params_dict = {"vec_param": query_vector}
results = redis_client.ft(index_name).search(q, query_params=params_dict)
# Print the results
if results.total > 0:
print(f"Top {topK} results for query: '{user_query}'\n")
for i, doc in enumerate(results.docs):
print(f"Result {i + 1}:")
print(f" Question: {doc.question}")
print(f" Answer: {doc.answer}")
print("\n" + "-"*40 + "\n")
else:
print(f"No results found for query: '{user_query}'")
result:
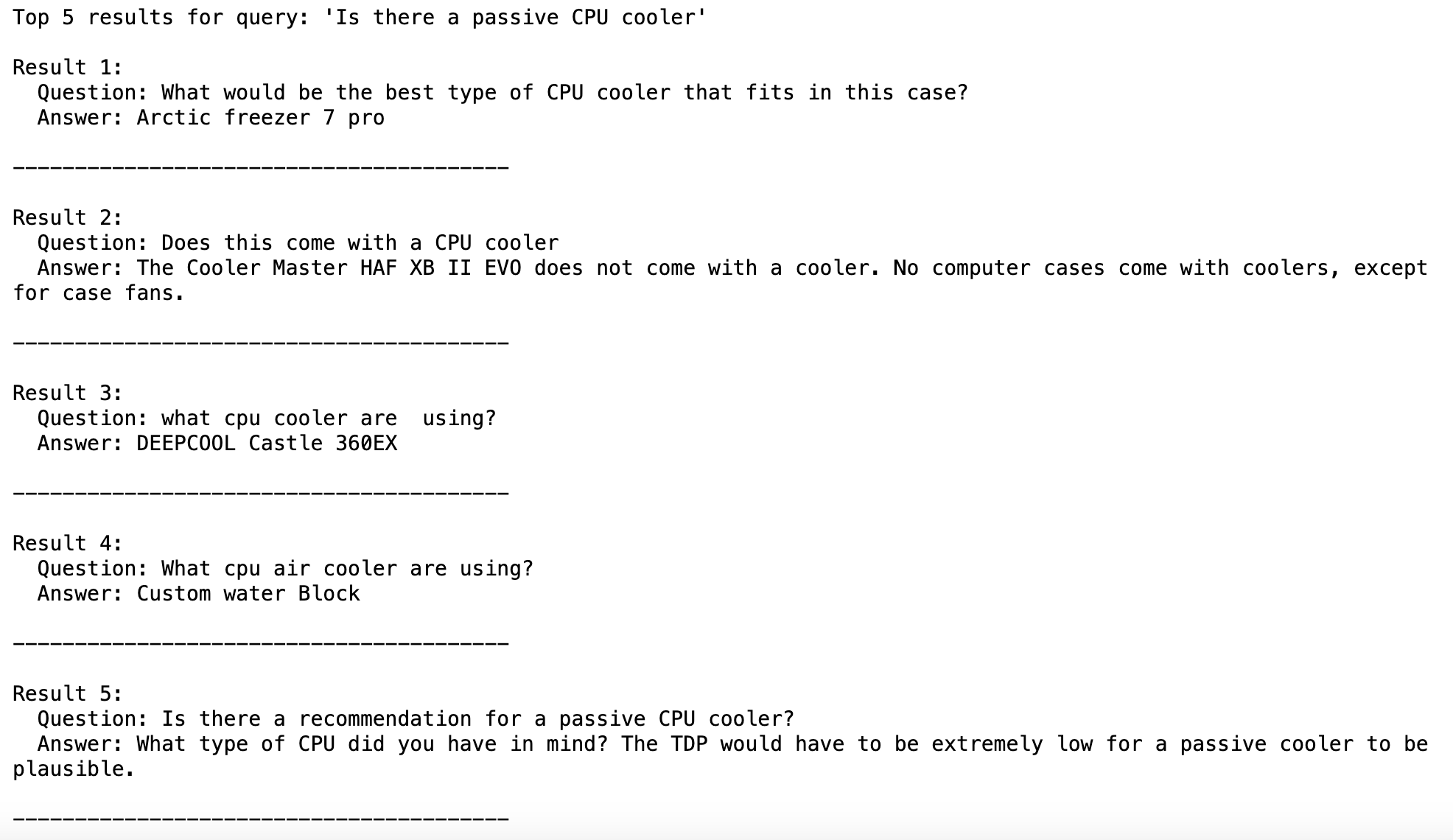
Conclusion
In this tutorial, we’ve demonstrated how to set up and use Amazon MemoryDB for real-time vector search. By leveraging its in-memory performance and Redis compatibility, MemoryDB provides an ideal environment for applications that require fast and reliable vector search capabilities. Whether you’re building recommendation engines, search systems, or AI-driven applications, Amazon MemoryDB can help you meet the demands of real-time data processing.
If you’re interested in exploring further, consider integrating MemoryDB with other AWS services, such as Amazon Sagemaker for machine learning or AWS Lambda for serverless computing, to build even more powerful and scalable applications.
For any questions and consultation, reach out at nurbol.sakenov@outlook.com


