
Understanding Vector Databases: Generative AI Usecase
- ai
- April 14, 2024
In the rapidly evolving world of data management, vector databases have emerged as a powerful tool for handling complex data types like images, audio, and documents. These databases leverage the concept of vectors to store and process data, enabling faster and more efficient retrieval of information. This blog post will introduce vector databases, covering everything from understanding vectors, to inserting data into a vector database, and using AI applications to retrieve data from a vector database with queries.
Table of Contents
What are Vectors?
Vectors are mathematical representations that store data in a format that a computer can understand and process efficiently. In simple terms, a vector is an array of numbers. These numbers can represent various features of data objects, such as the intensity of pixels in an image, the frequencies in audio, or the semantic features of text.
Example of a Vector:
Consider a simple example where we vectorize a small grayscale image. This image might be represented as a 3x3 pixel grid, and each pixel has a brightness value from 0 (black) to 255 (white). The vector representation of this image could be:
[120, 135, 150,
160, 175, 190,
200, 215, 230]
Each number here represents the grayscale intensity of a pixel in the image.
How Can Vector Databases Enhance AI Capabilities?
Semantic Information Retrieval
Vector databases excel in handling and retrieving high-dimensional data, which is particularly useful for tasks that require understanding and manipulating semantic content.
Data (like text or images) is transformed into vectors using embedding techniques, which capture semantic meanings and nuances. For example, text data is processed through models like BERT or GPT to generate embeddings that reflect contextual similarities.
Efficient Search
When a query is made, the vector database can quickly retrieve items whose embeddings are closest to the query embedding, thus ensuring that the responses are semantically related to the input. This is particularly useful in scenarios like searching for similar documents, recommending content, or even fetching relevant historical data to enhance response quality.
Long-term Memory for AI
Vector databases can also play a crucial role in simulating long-term memory for AI systems, enabling them to recall and utilize past interactions or learned information.
By storing embeddings of past interactions, a vector database can allow an AI to remember and reference previous conversations. This is crucial for applications requiring continuity over sessions, such as digital assistants, personalized recommendations, or customer service bots.
With access to historical data, AI can maintain context over longer conversations or across multiple sessions, improving the relevance and personalization of its responses.
Vectorization Pipeline Example
The process of inserting or updating data in a vector database involves several steps, each crucial for ensuring that the data is stored efficiently and can be retrieved quickly. Here is an example pipeline:
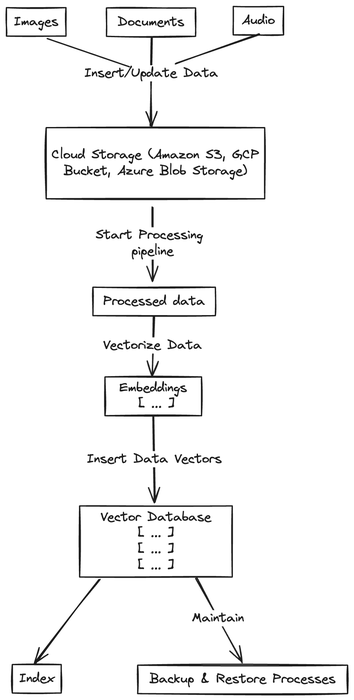
Inserting/Updating in Cloud Storage
The first step involves storing the original data, such as images, documents, or audio files, in cloud storage. This provides a secure and scalable way to manage the raw data.
Data Processing
Before the actual vectorization, the raw data undergoes preliminary processing. This might include:
- Cleaning data to remove noise or irrelevant information.
- Standardizing or normalizing data to ensure consistency.
- Extracting features that are significant for the subsequent vectorization step.
Vectorizing Data
In this crucial step, algorithms transform the processed data into vectors. This transformation depends heavily on the type of data:
- For images, techniques like CNN (Convolutional Neural Networks) might be used to detect patterns and features.
- For text, models like Word2Vec or BERT might convert text into semantic vectors.
- For audio, Fourier transforms or other frequency analysis techniques might be applied.
Inserting Data Vectors into the Vector Database
Once the data is vectorized, these vectors are inserted into the vector database. The database is designed to handle these vector forms efficiently, enabling quick searches and retrieval.
Indexing Data
To optimize the search and retrieval process, the vectors are indexed. Indexing involves organizing data in a way that optimizes speed and performance. Techniques like KD-trees, R-trees, or more complex structures like HNSW (Hierarchical Navigable Small World graphs) are commonly used for indexing vectors.
Querying Data from Vector Database
Here’s an overview of how this process generally unfolds:
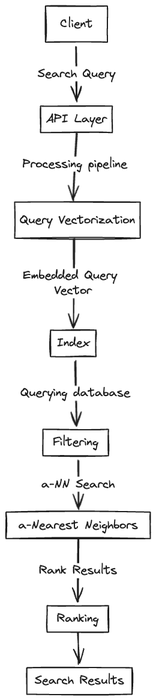
Client Query Submission
The process starts with a user or client system submitting a query. This query might be in the form of text, an image, or any other data type that the system is designed to process.
Preprocessing
The raw data from the query is cleaned and normalized. For text, this might include removing punctuation, lowercasing, or other forms of text normalization. Depending on the type of data, relevant features are extracted. For instance, in the case of images, this might involve applying filters and extracting edges or textures.
Vectorization
Before querying, the data (such as images, text, or other media) needs to be converted into a form that the vector database can understand. This involves transforming the data into high-dimensional vectors using models such as deep neural networks or other machine learning algorithms. Each vector represents different features or attributes of the data.
Indexing
Once data is vectorized, the next step is to index these vectors for efficient retrieval. Indexing is crucial because it optimizes the search process, especially in a high-dimensional space. Index structures such as KD-trees, HNSW (Hierarchical Navigable Small World graphs), or product quantization are used to enable faster search operations by organizing the vectors in a way that balances the trade-off between accuracy and search speed.
Querying and Filtering
When a query is made (usually also in vector form), the database can apply initial filters based on metadata or specific attributes before performing a vector search. This filtering step reduces the search space or scope by excluding vectors that don’t meet the query’s criteria (e.g., filtering images by date or excluding documents not within a certain topic).
Approximate Nearest Neighbor (ANN) Search
The filtered set of vectors (or the entire dataset if no filters are applied) undergoes an ANN search to find the most similar vectors to the query vector. ANN search is a method that efficiently finds vectors that are “near” to the target vector in the high-dimensional space without needing to perform exact distance calculations across the entire dataset, which would be computationally expensive.
Ranking
After the ANN search identifies a set of candidate vectors, these results are ranked. Ranking is typically based on the similarity measure, such as cosine similarity or Euclidean distance, between the query vector and each of the candidate vectors. The results are then sorted by this similarity score, with the closest matches ranked highest.
Retrieval
Finally, the top-ranked items are retrieved from the database. These items are what the query returns as the most relevant results based on the vector similarity to the query.
For any questions and consultation, reach out at nurbol.sakenov@outlook.com


