Near real time game events integration into Snowflake with Snowpipe and Amazon Kinesis
- snowflake , aws
- March 31, 2023
Amazon Kinesis and Snowpipe are two powerful services that can be used together to deliver near real-time data processing. Kinesis is a real-time data streaming service that allows you to collect, process, and analyse large amounts of data in real-time. Snowpipe is a data integration service that allows you to load data from various sources into your data warehouse in near real-time.
In this guide, we will build an ingestion pipeline using Kinesis and Snowpipe to create a powerful data pipeline for a theoretical mobile game that produces events every second. This will be an end-to-end solution where we will first design a sample in-app purchase (IAP) event for posting to the API endpoint, design a CloudFormation template to provision necessary resources on AWS, and finally deploy the CloudFormation template using the boto3 library in Python and create a Snowpipe integration using snowflake.connector in Python.
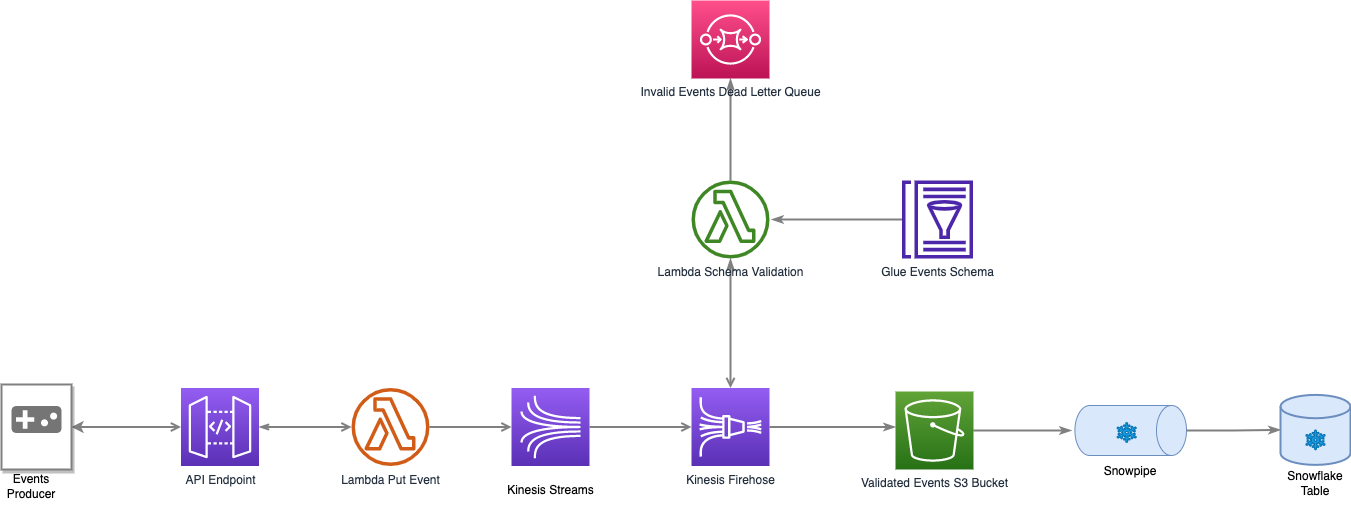
Table of Contents
Preparing a sample event and test script
Let’s suppose we have a gaming app that produces IAP events similar to below:
{
"event_version":"1.0.0",
"event_id":"80886dd4-3de2-41c7-88aa-ddfd315d1dd8",
"event_name":"iap_transaction",
"event_timestamp":"2023-03-28T21:51:56.803091",
"app_version":"1.1.0",
"event_data":{
"item_version":2,
"country_id":"JAPAN",
"currency_type":"JPY",
"bundle_name":"Collector's Bundle",
"amount":19.99,
"platform":"nintendo_switch",
"transaction_id":"1f1f9097-7f89-4338-94c8-75c52c6b53f6"
}
}
The event payload will serve as our basis. To make events posted to the API look realistic, the following script randomizes event values. It takes two arguments: an api-url to post events, and an invalid-events marker, which will be used to post corrupt events to test the schema validation.
import numpy as np
import random
import uuid
import datetime
import requests
import json
import argparse
def parse_cmd_line():
"""Parse the command line and extract the necessary values."""
parser = argparse.ArgumentParser(description='Send data to an api gateway for Kinesis stream for analytics. By default, the script '
'will send events infinitely. To stop the script, press Ctrl+C.')
parser.add_argument('--api-url', required=True, type=str,
dest='api_gateway_url', help='api gateway url to post events to')
parser.add_argument('--invalid-events', action='store_true', dest='invalid_events',
help='if provided generates invalid events')
return parser.parse_args()
def getUUIDs(dataType, count):
uuids = []
for i in range(0, count):
uuids.append(str(uuid.uuid4()))
return uuids
def getIapData():
purchase_bundles = [{"name": "Starter Bundle", "price": 4.99},
{"name": "Power-Up Bundle", "price": 9.99},
{"name": "Collector's Bundle", "price": 19.99},
{"name": "Special Event Bundle", "price": 14.99},
{"name": "VIP Bundle", "price": 49.99}]
countries = [
'UNITED STATES',
'UK',
'JAPAN',
'SINGAPORE',
'AUSTRALIA',
'BRAZIL',
'SOUTH KOREA',
'GERMANY',
'CANADA',
'FRANCE'
]
currencies = {
'UNITED STATES': 'USD',
'UK': 'GBP',
'JAPAN': 'JPY',
'SINGAPORE': 'SGD',
'AUSTRALIA': 'AUD',
'BRAZIL': 'BRL',
'SOUTH KOREA': 'KRW',
'GERMANY': 'EUR',
'CANADA': 'CAD',
'FRANCE': 'EUR'
}
platforms = [
'nintendo_switch',
'ps4',
'xbox_360',
'iOS',
'android',
'pc',
]
country_id = str(np.random.choice(countries, 1, p=[
0.3, 0.1, 0.2, 0.05, 0.05, 0.02, 0.15, 0.05, 0.03, 0.05])[0])
bundle = np.random.choice(purchase_bundles, 1, p=[
0.2, 0.2, 0.2, 0.2, 0.2])[0]
iap_transaction = {
'event_data': {
'item_version': random.randint(1, 2),
'country_id': country_id,
'currency_type': currencies[country_id],
'bundle_name': bundle['name'],
'amount': bundle['price'],
'platform': platforms[random.randint(0, 5)],
'transaction_id': str(uuid.uuid4())
}
}
return iap_transaction
def generate_event(valid_events):
event_name = 'iap_transaction'
event_data = getIapData()
event = {
'event_version': '1.0.0',
'event_id': str(uuid.uuid4()),
'event_name': event_name,
'event_timestamp': datetime.datetime.now().isoformat(),
'app_version': str(np.random.choice(['1.0.0', '1.1.0', '1.2.0'], 1, p=[0.05, 0.80, 0.15])[0])
}
if not invalid_events:
event.update(event_data)
return event
if __name__ == "__main__":
args = parse_cmd_line()
api_gateway_url = args.api_gateway_url
invalid_events = args.invalid_events
print('posting events..')
while True:
iap_event = generate_event(invalid_events)
iap_event_json = json.dumps(iap_event)
headers = {
"Content-Type": "application/json",
"Accept": "application/json"
}
# Post the IAP event to API Gateway
response = requests.post(
api_gateway_url, headers=headers, data=iap_event_json)
if response.status_code != 200:
print(response)
print(response.text)
Cloudformation
To get started. we will first define parameters and outputs from the template. Our inputs will be the number of kinesis shards to provision and firehose interval in seconds for buffering events before sending to s3.
As cloudformation outputs we want to have pipeline role arn, which will be used later in creating snowpipe, bucket name where validated events are stored and api invoke url to which we will be posting events from [1].
Parameters:
KinesisShards:
Type: Number
Description: Shards count for Kinesis Streams
Default: 1
MinValue: 1
MaxValue: 10
FirehoseInterval:
Type: Number
Description: Firehose buffering data before delivering S3
Default: 60
MinValue: 60
MaxValue: 900
Outputs:
RoleArn:
Value: !GetAtt 'PipelineRole.Arn'
BucketName:
Value: !Ref S3BucketRawData
ApiGatewayInvokeUrl:
Value: !Sub "https://${HttpApi}.execute-api.${AWS::Region}.amazonaws.com/prod/put-record"
a) api gateway:
For simplicity purposes, our api gateway will be without authorisation. In the following, we create an api, a stage and define integration with lambda. Finally, we define the route to post events:
HttpApi:
Type: AWS::ApiGatewayV2::Api
Properties:
Name: !Sub '${AWS::StackName}-api'
ProtocolType: HTTP
ApiStage:
Type: AWS::ApiGatewayV2::Stage
Properties:
ApiId: !Ref HttpApi
StageName: prod
Description: Live Stage
AutoDeploy: true
Integration:
Type: AWS::ApiGatewayV2::Integration
Properties:
ApiId: !Ref HttpApi
Description: Lambda proxy integration
IntegrationType: AWS_PROXY
IntegrationMethod: POST
PayloadFormatVersion: "2.0"
IntegrationUri: !Sub 'arn:${AWS::Partition}:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${HttpApiLambda.Arn}/invocations'
ApiRoute:
Type: AWS::ApiGatewayV2::Route
Properties:
ApiId: !Ref HttpApi
RouteKey: "POST /put-record"
AuthorizationType: NONE
Target: !Join
- /
- - integrations
- !Ref Integration
b) lambda function for kinesis
We will deploy the lambda function using inline code, the lambda is quite simple and accepts an event from the api gateway and puts the event into the kinesis stream.
HttpApiLambda:
Type: AWS::Serverless::Function
Properties:
Handler: index.handle_event
Runtime: "python3.8"
Timeout: 100
MemorySize: 160
Environment:
Variables:
KINESIS_STREAM_NAME: !GetAtt Kinesis.Arn
Role: !GetAtt 'PipelineRole.Arn'
InlineCode: |
import json
import os
import uuid
import time
import boto3
def extract_body_dict_with_metadata(event: dict) -> dict:
if 'requestContext' not in event:
return None
if 'body' not in event:
return None
payload = json.loads(event.get('body'))
payload['server_received_time'] = int(time.time())
return payload
def create_response(status: int, msg: str):
return {
"isBase64Encoded": False,
"statusCode": status,
"body": f'{{"message": "{msg}"}}',
"headers": {
"Content-Type": "application/json"
}
}
def send_body_to_kinesis(kinesis_stream_name, body_dict):
kinesis = boto3.client('kinesis')
encoded_data = (json.dumps(body_dict) + '\n').encode('utf-8')
kinesis.put_record(StreamName=kinesis_stream_name, Data=encoded_data, PartitionKey=str(uuid.uuid4()))
def handle_event(event, context):
kinesis_stream_name = os.getenv('KINESIS_STREAM_NAME').split('/')[1]
body_dict = extract_body_dict_with_metadata(event)
if not body_dict:
return create_response(400, 'Invalid request')
try:
send_body_to_kinesis(kinesis_stream_name, body_dict)
print('sent to kinesis')
except Exception as e:
return create_response(500, "Couldn't process the request.")
return create_response(200, 'OK')
in addition, we will attach permission to invoke the function:
HttpApiLambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref HttpApiLambda
Action: "lambda:InvokeFunction"
Principal: apigateway.amazonaws.com
c) kinesis streams and kinesis firehose
The number of shards for the kinesis stream and firehose buffering interval will be defined by our inputs. The kinesis firehose will have a data transformation lambda, we will use the function arn in the firehose definition to invoke lambda.
Kinesis:
Type: AWS::Kinesis::Stream
Properties:
Name: !Sub '${AWS::StackName}-kinesisStream'
RetentionPeriodHours: 24
ShardCount: !Ref KinesisShards
Firehose:
DependsOn:
- PipelineRolePolicy
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt 'Kinesis.Arn'
RoleARN: !GetAtt 'PipelineRole.Arn'
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt 'S3BucketRawData.Arn'
BufferingHints:
IntervalInSeconds: !Ref FirehoseInterval
SizeInMBs: 5
CompressionFormat: GZIP
RoleARN: !GetAtt 'PipelineRole.Arn'
ProcessingConfiguration:
Enabled: true
Processors:
- Type: Lambda
Parameters:
- ParameterName: "LambdaArn"
ParameterValue: !GetAtt ValidateEventsLambda.Arn
d) lambda function event validation
The lambda function will reference an AWS Glue Schema to validate an event. If the event does not pass the schema check, it will be sent to the SQS queue for later processing. All the events after processing will be put back into the firehose, the ones marked as Dropped will not be delivered to the S3 bucket accessed by snowpipe:
ValidateEventsLambda:
Type: AWS::Serverless::Function
Properties:
Handler: index.lambda_handler
Runtime: "python3.8"
Timeout: 100
MemorySize: 160
Environment:
Variables:
SCHEMA_ARN: !GetAtt GlueSchema.Arn
QUEUE_URL: !GetAtt UnprocessedEventsDLQ.QueueUrl
Role: !GetAtt 'PipelineRole.Arn'
InlineCode: |
import subprocess
import sys
subprocess.call('pip install jsonschema -t /tmp/ --no-cache-dir'.split(), stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
sys.path.insert(1, '/tmp/')
import json
import boto3
from jsonschema import validate, ValidationError
import base64
import os
sqs = boto3.client('sqs')
glue = boto3.client('glue')
def get_schema(schema_name):
# Get the schema from the Glue Schema Registry
schema_arn = os.getenv('SCHEMA_ARN')
# Retrieve the schema metadata
schema_metadata = glue.get_schema_version(
SchemaId={
'SchemaArn': schema_arn
},
SchemaVersionNumber={
'LatestVersion': True
}
)
# Retrieve the schema content
schema_content = schema_metadata['SchemaDefinition']
return json.loads(schema_content)
def lambda_handler(event, context):
schema = get_schema('iap_transaction')
queue_url = os.getenv('QUEUE_URL')
output = []
valid = 0
invalid = 0
for record in event['records']:
decoded_payload = base64.b64decode(record['data']).decode('utf-8')
try:
payload = json.loads(decoded_payload)
validate(payload, schema)
except ValidationError as e:
# Record is invalid, send it to the SQS dead letter queue
invalid +=1
error = str({'error':e})
sqs.send_message(
QueueUrl=queue_url,
MessageBody=decoded_payload+error,
)
output_record = {
'recordId': record['recordId'],
'result': 'Dropped',
'data': record['data']
}
output.append(output_record)
else:
valid +=1
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(decoded_payload.encode('utf-8')).decode('utf-8')
}
output.append(output_record)
print(f'{valid} validated successfully\n{invalid} sent to DLQ')
return {'records': output}
and the permission to invoke the function:
ValidateEventsLambdaPermission:
Type: AWS::Lambda::Permission
Properties:
Action: 'lambda:InvokeFunction'
FunctionName: !Ref ValidateEventsLambda
Principal: firehose.amazonaws.com
e) SQS for storing invalid events
UnprocessedEventsDLQ:
Type: AWS::SQS::Queue
Properties:
SqsManagedSseEnabled: false
MessageRetentionPeriod: 1209600
VisibilityTimeout: 43200
f) s3 bucket for storing valid events
S3BucketRawData:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: !Sub '${AWS::StackName}-data'
g) role & policies
For demo purposes, we will use only one role and policy for the entire pipeline.
PipelineRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub '${AWS::StackName}-role'
Description: IAM role for Lambda functions
Path: /
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
- firehose.amazonaws.com
- kinesis.amazonaws.com
Action:
- 'sts:AssumeRole'
PipelineRolePolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
ManagedPolicyName: !Sub '${AWS::StackName}-policy'
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Action:
- 'logs:PutLogEvents'
- 'logs:CreateLogStream'
- 'logs:CreateLogGroup'
- 'cloudwatch:PutMetricData'
Resource: "*"
- Effect: "Allow"
Action:
- 'kinesis:*'
Resource: !GetAtt 'Kinesis.Arn'
- Effect: "Allow"
Action:
- 'lambda:*'
Resource:
- !GetAtt 'ValidateEventsLambda.Arn'
- !GetAtt 'HttpApiLambda.Arn'
- Effect: "Allow"
Action:
- 'glue:*'
Resource: !GetAtt GlueSchema.Arn
- Effect: "Allow"
Action:
- 'glue:GetSchemaVersion'
Resource: "*"
- Effect: "Allow"
Action:
- 's3:*'
Resource:
- !GetAtt 'S3BucketRawData.Arn'
- !Sub '${S3BucketRawData.Arn}/*'
- Effect: "Allow"
Action:
- 'sqs:SendMessage'
Resource: "*"
Roles: [!Ref PipelineRole]
h) glue schema
In this step, we define a glue schema for events validation. I will mark all fields as required intentionally to make sure there are no fields with null values and allow additional properties to account for new fields.
GlueSchema:
Type: AWS::Glue::Schema
Properties:
Name: !Sub '${AWS::StackName}-schema'
DataFormat: JSON
Compatibility: BACKWARD
SchemaDefinition: |
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/iap_transaction.json",
"type": "object",
"title": "iap_transaction",
"required": [
"event_version",
"event_id",
"event_name",
"event_timestamp",
"app_version",
"event_data"
],
"additionalProperties": true,
"properties": {
"event_version": {
"type": "string"
},
"event_id": {
"type": "string"
},
"event_name": {
"type": "string"
},
"event_timestamp": {
"type": "string",
"format": "date-time"
},
"app_version": {
"type": "string"
},
"event_data": {
"type": "object",
"required": [
"item_version",
"country_id",
"currency_type",
"bundle_name",
"amount",
"platform",
"transaction_id"
],
"additionalProperties": true,
"properties": {
"item_version": {
"type": "integer"
},
"country_id": {
"type": "string"
},
"currency_type": {
"type": "string"
},
"bundle_name": {
"type": "string"
},
"amount": {
"type": "number",
"minimum": 0
},
"platform": {
"type": "string"
},
"transaction_id": {
"type": "string",
"pattern": "^[a-fA-F0-9-]{36}$"
}
}
}
}
}
Deploying to AWS & Snowflake
In this section, we will be deploying our cloudformation template and creating resources in Snowflake. For ease of management, I will be using in python boto3 library and snowflake connector to create all resources.
To get started, let’s import necessary packages and initiate aws and snowflake connection:
import os
import snowflake.connector
import boto3
from dotenv import load_dotenv
load_dotenv()
# Connect to Snowflake
conn = snowflake.connector.connect(
user=os.getenv('SNOWFLAKE_USER'),
password=os.getenv('SNOWFLAKE_PASSWORD'),
account=os.getenv('SNOWFLAKE_ACCOUNT'),
role='ACCOUNTADMIN'
)
# Create a cursor
cur = conn.cursor()
# AWS session
session = boto3.Session(
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
)
In order to create a storage integration necessary for snowpipe, we will need ACCOUNTADMIN role assigned to the snowflake user.
Next, we will deploy our template to AWS and store outputs, which will be later used for snowflake resources:
# Deploy stack
cf_client = session.client('cloudformation', region_name='eu-central-1')
stack_name = 'game-events-pipeline'
template_body = open('cf_kinesis_pipeline.yaml').read()
capabilities = ['CAPABILITY_AUTO_EXPAND', 'CAPABILITY_NAMED_IAM']
response = cf_client.create_stack(
StackName=stack_name,
TemplateBody=template_body,
Capabilities=capabilities,
Parameters=[
{
'ParameterKey': 'KinesisShards',
'ParameterValue': '1'
},
{
'ParameterKey': 'FirehoseInterval',
'ParameterValue': '60'
}
]
)
cf_outputs = {}
while True:
stack_status = cf_client.describe_stacks(StackName=stack_name)['Stacks'][0]['StackStatus']
if stack_status == 'CREATE_FAILED' or stack_status == 'ROLLBACK_IN_PROGRESS':
events = cf_client.describe_stack_events(StackName=stack_name)
error_event = next((event for event in events['StackEvents'] if event['ResourceStatus'] == 'CREATE_FAILED' or event['ResourceStatus'] == 'ROLLBACK_IN_PROGRESS'), None)
error_message = error_event['ResourceStatusReason']
print('Stack status failed. Error message:\n' + error_message)
break
elif stack_status == 'CREATE_COMPLETE':
stack_outputs = cf_client.describe_stacks(StackName=stack_name)['Stacks'][0]['Outputs']
for output in stack_outputs:
key = output['OutputKey']
value = output['OutputValue']
cf_outputs[key] = value
print('stack created')
break
print(cf_outputs)
Once the stack is successfully created, we will create a storage integration with aws role arn and bucket name obtained from stack creation:
# Create a storage integration
s3_int_name = 's3_int_game_data'
query = f"""
CREATE OR REPLACE STORAGE INTEGRATION {s3_int_name}
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = '{cf_outputs['RoleArn']}'
STORAGE_ALLOWED_LOCATIONS = ('s3://{cf_outputs['BucketName']}');
"""
cur.execute(query)
# Retrieve the Snowflake external ID and user role
cur.execute(f"describe integration {s3_int_name}")
result = cur.fetchall()
for i in result:
if i[0]=='STORAGE_AWS_IAM_USER_ARN':
storage_aws_iam_user_arn = i[2]
elif i[0]=='STORAGE_AWS_EXTERNAL_ID':
storage_aws_external_id = i[2]
After the storage integration is created, we will need to update the trust policy of the aws role with storage_aws_iam_user_arn and storage_aws_external_id from above in order to allow connection between Snowflake and AWS.
# Update the trust policy of the IAM role
iam = session.client('iam')
role_name = cf_outputs['RoleArn'].split('/')[-1]
assume_role_policy_document = json.dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": storage_aws_iam_user_arn,
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": storage_aws_external_id
}
}
},
{
"Effect": "Allow",
"Principal": {
"Service": [
"lambda.amazonaws.com",
"firehose.amazonaws.com",
"kinesis.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
})
response = iam.update_assume_role_policy(
RoleName=role_name,
PolicyDocument=assume_role_policy_document
)
if response['ResponseMetadata']['HTTPStatusCode']==200:
print('updated trust policy')
With the connection setup out of the way, we can proceed by creating an iap table in snowflake for data ingestion:
the next commands assume that database streaming_db and schema raw_dev exist. Replace database and schema names with existing ones.
# create table
sf_table = "streaming_db.raw_dev.iap"
cur.execute(f"""
CREATE TABLE IF NOT EXISTS {sf_table} (
event_version VARCHAR(10),
event_id VARCHAR(36),
event_name VARCHAR(20),
event_timestamp TIMESTAMP_NTZ,
app_version VARCHAR(10),
event_data VARIANT,
server_received_time NUMBER
);
""")
Next, we will create a staging for our table:
# create stage
cur.execute("USE DATABASE streaming_db;")
cur.execute("USE SCHEMA raw_dev;")
stage_name = 'iap_stage'
cur.execute(f"""
CREATE OR REPLACE STAGE {stage_name}
URL = 's3://{cf_outputs['BucketName']}'
STORAGE_INTEGRATION = {s3_int_name}
""")
After staging is created, we can create a snowpipe and set auto_ingest to true for continuous data integration:
# create pipe
pipe_name = "iap_pipe"
cur.execute(f"""
CREATE OR REPLACE PIPE {pipe_name}
AUTO_INGEST = TRUE
AS
COPY INTO {sf_table}
FROM @streaming_db.raw_dev.{stage_name}
FILE_FORMAT = (type ='JSON',
compression=gzip,
strip_outer_array=true)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
""")
Finally, we will use SQS queue arn of the created pipe to trigger ingestion once there are new files added in our S3 bucket:
# Retrieve sqs queue arn
cur.execute(f"describe pipe {pipe_name}")
result = cur.fetchall()
for i in result[0]:
if str(i)[:3] == 'arn':
arn_sqs_queue = i
# Set bucket notification
queue_config = {
'Id': 'bucket_level_notification',
'Queue': arn_sqs_queue,
'Events': [
's3:ObjectCreated:*',
],
}
bucket_notification_config = {
'QueueConfiguration': queue_config
}
s3 = session.client('s3')
s3.put_bucket_notification(
Bucket=cf_outputs['BucketName'],
NotificationConfiguration=bucket_notification_config
)
if response['ResponseMetadata']['HTTPStatusCode']==200:
print('added bucket notification')
Testing the entire pipeline
Here comes my favourite part, we will be posting events to the api gateway and check if the valid events land in our s3 bucket and invalid events are sorted out to SQS dead letter queue.
Starting with valid events:
python generate_event.py --api-url <api-invoke-url>
After a minute we can see the event files written in the S3 bucket:
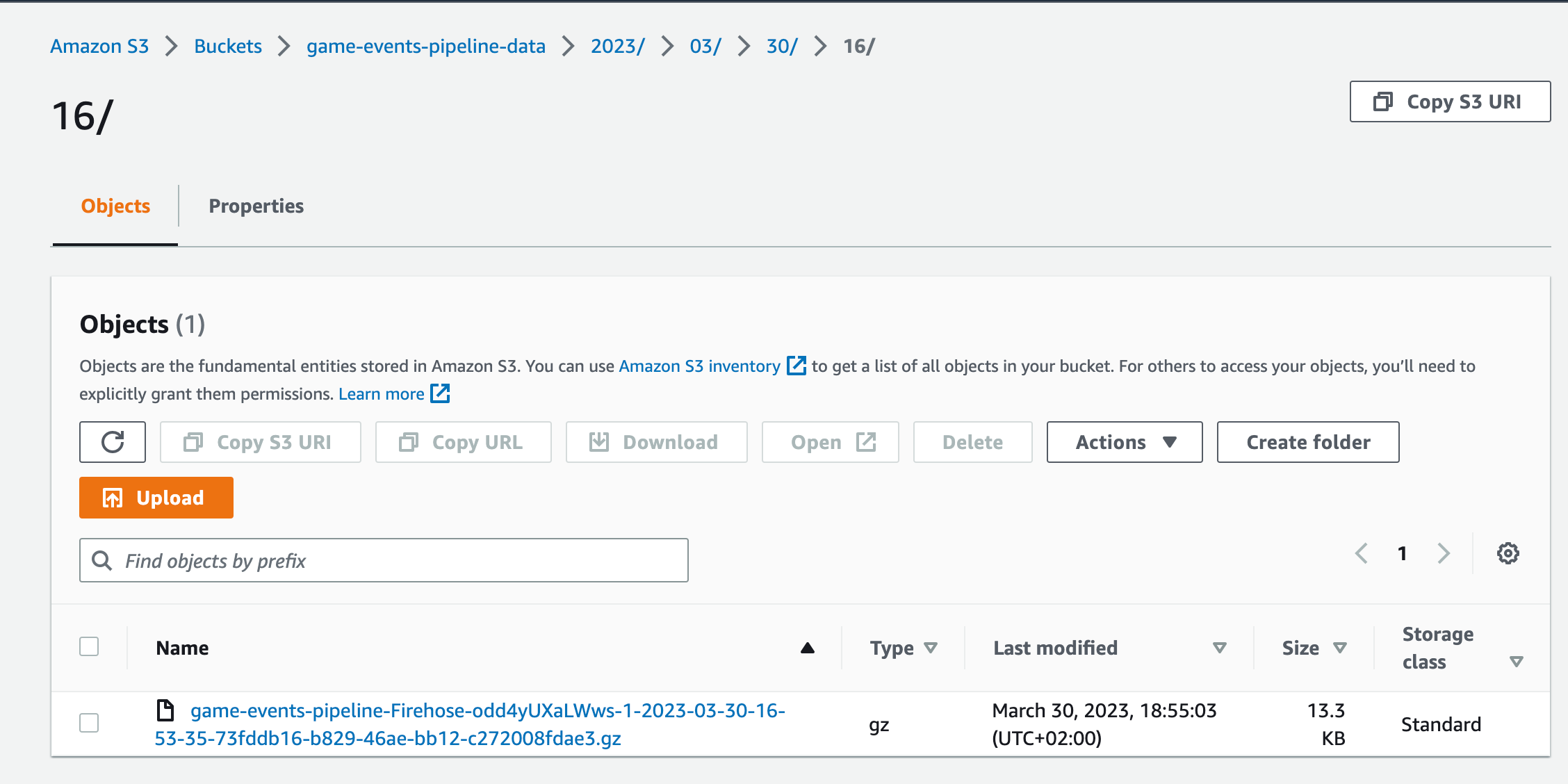
And snowpipe also ingesting files into our table:
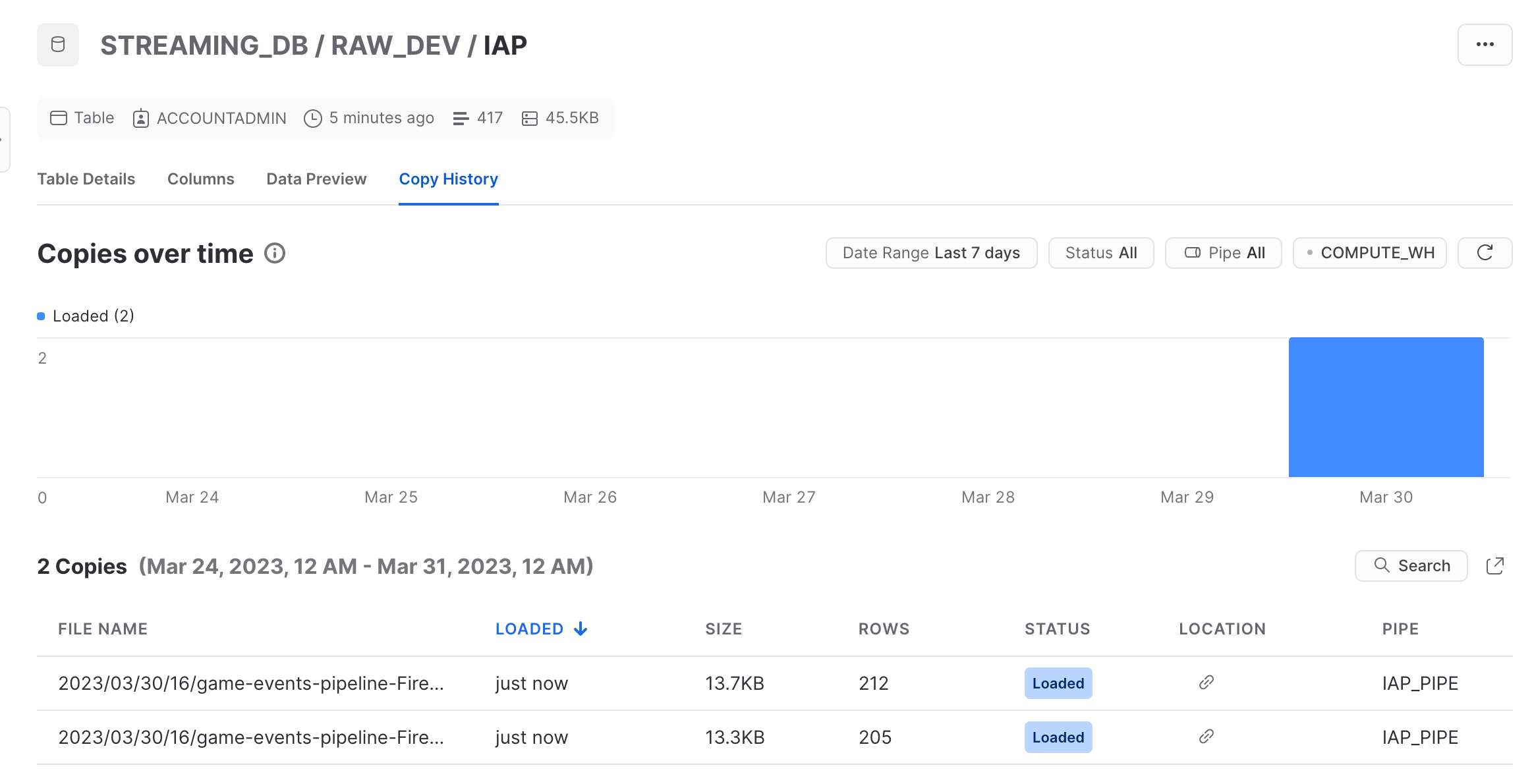
Closer look at the table:
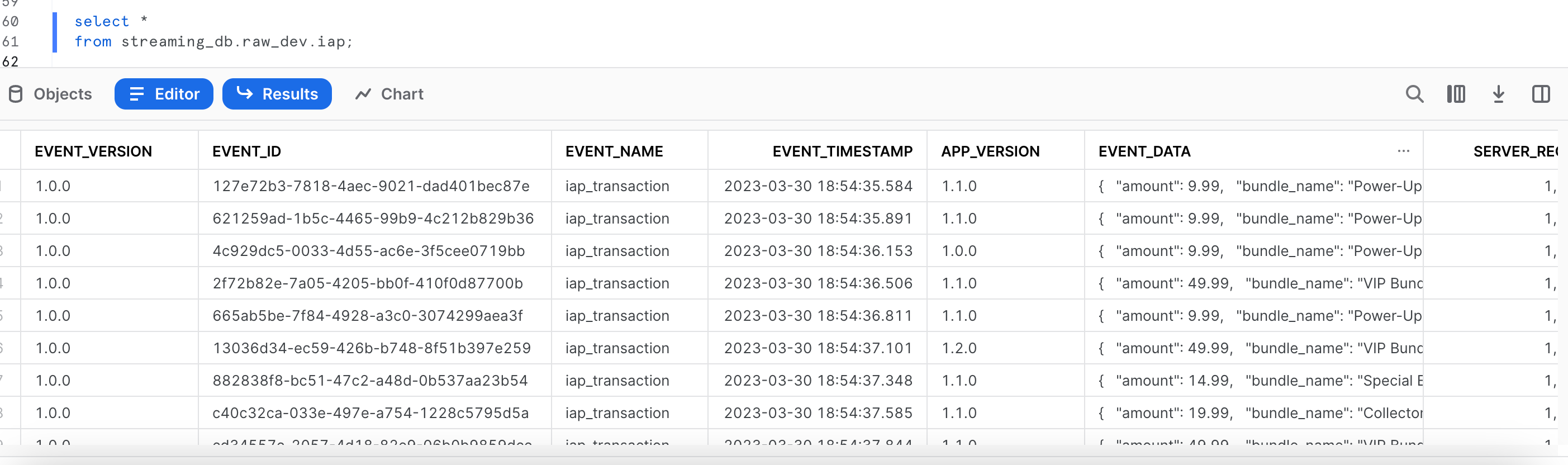
Now, lets start sending invalid events along with valid events:
python generate_event.py --api-url <api-invoke-url> --invalid-events
From the lambda logs, we can start seeing that some events are already sent to the SQS queue:

Let’s poll the SQS queue to see the reason:
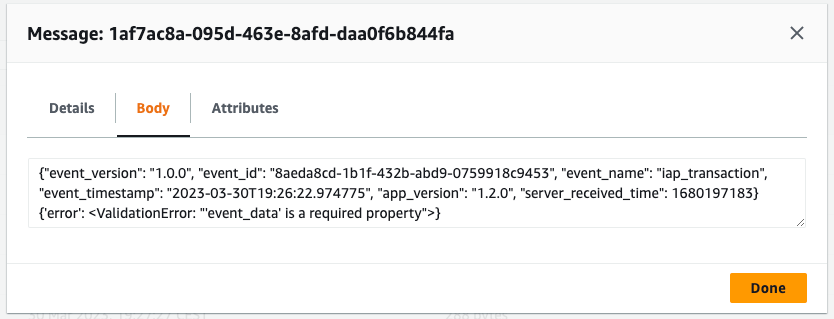
As expected, the schema validation failed because event_data is missing from the payload. To be sure, let’s query the table in Snowflake and count events with missing event_data field:
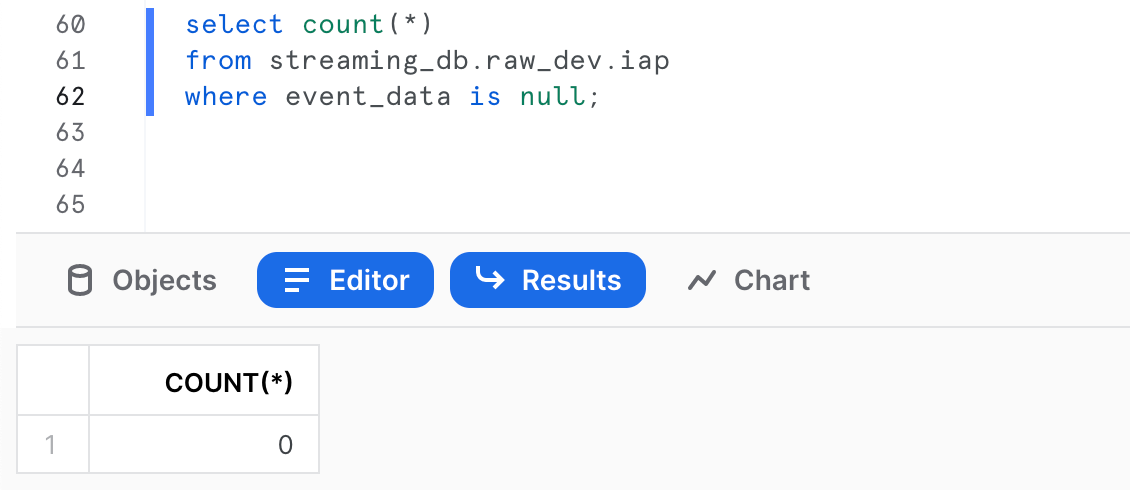
All looks good!
To avoid unexpected bills, let’s clean up our environments:
# Clean up SF
cur.execute(f"drop stage {stage_name}")
cur.execute(f"drop integration {s3_int_name}")
cur.execute(f"drop table {sf_table}")
cur.execute(f"drop pipe {pipe_name}")
print('cleaned snowflake')
# Clean up AWS
# Empty bucket before deleting
response = cf_client.delete_stack(
StackName=stack_name
)
if response['ResponseMetadata']['HTTPStatusCode']==200:
print('cleaned up AWS')
Production deployment considerations
When planning for the deployment into production environment, it’s important to consider several key factors. Below are some considerations:
Costs — not all events need to be ingested near real-time, but some do: Ingesting all events in real-time can be expensive. Make sure to consider which events need to be ingested immediately and which ones can be processed at a later time.
Roles and policies: It is essential to set up roles and policies for each service to ensure that the right level of access and permissions are given. For example, only the necessary services should have access to Kinesis streams and Lambda functions. This reduces the risk of unauthorised access and ensures the confidentiality of the data.
API Gateway authorisation: Authorisation is important to ensure that only authorised users and applications can access your API. Make sure to properly configure your API Gateway to require authentication and authorisation as needed.
Logging: Proper logging is critical to ensure that your application is running smoothly and to identify any issues that may arise. Make sure that your application logs are being monitored and that they are easily accessible when needed.
Throttling of API Gateway and Kinesis: Throttling is an important factor to consider when deploying to production environment. Make sure to properly provision resources to prevent your application from being overwhelmed with requests and to ensure that your resources are being used efficiently.
Continuous integration and deployment (CI/CD) for Lambda deployments: CI/CD is a best practice for deploying Lambda functions to production environments. It ensures that your code is being tested and deployed in a controlled and consistent manner.
Sorting of events in case more than one event type is posted to the same API: If your API is receiving multiple types of events, make sure to sort them properly to ensure that they are handled correctly. This can help to avoid any unexpected behavior or errors.
The article resources for this guide can be found in the following GitHub repository: https://github.com/nsakenov/kinesis-snowpipe
For any questions and consultation, reach out at nurbol.sakenov@outlook.com