
21x Speedup in Pandas with Zero Code Changes
- ai
- October 1, 2024
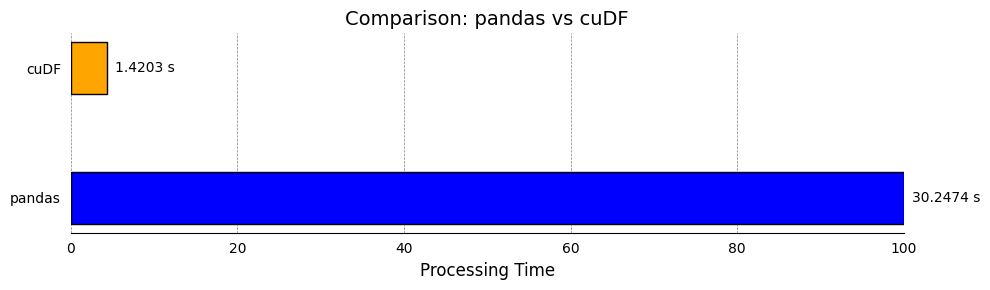
Last weekend, I experimented with cuDF’s Pandas Accelerator Mode on an Nvidia T4 GPU. The results were quite impressive, especially considering that no code changes were required from the user. cuDF performed 21x faster on a group-by operation with a dataset containing 70 million rows.
Generating the Dataset
To begin, I generate a large synthetic dataset containing 70 million rows. The dataset has three columns:
col1is filled with random floating-point numbers.col2contains random integers ranging from 0 to 100.col3holds random categorical values (‘A’, ‘B’, ‘C’, ‘D’).
This dataset simulates a real-world scenario where I might need to perform large-scale data analysis. Once created, I save the dataset to a CSV file (large_dataset.csv) for use in both Pandas and cuDF.
data_size = 70000000
df = pd.DataFrame({
'col1': np.random.randn(data_size),
'col2': np.random.randint(0, 100, size=data_size),
'col3': np.random.choice(['A', 'B', 'C', 'D'], size=data_size)
})
df.to_csv('large_dataset.csv', index=False)
Timing the Operations
To measure how long each operation takes, I use a helper function called run_and_time. This function takes in an operation (in the form of a function) and logs its execution time. It starts a timer before running the operation, and once the operation finishes, it prints out the total time taken.
This makes it really easy to compare different operations and see which one performs better.
def run_and_time(func, operation_name):
print(f"Starting {operation_name}...")
start_time = time.time()
func()
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{operation_name} completed in {elapsed_time:.2f} seconds.")
return elapsed_time
Pandas Operation
For the Pandas operation, I read the dataset from the CSV file, perform a group-by operation on col3, and then sum the values in col2 for each group. This is a common task in data analysis and allows me to test how Pandas handles this type of aggregation on a large dataset.
def pandas_operation():
df = pd.read_csv('large_dataset.csv')
result_pandas = df.groupby('col3')['col2'].sum()
cuDF Operation
Next, I do the same thing with cuDF. cuDF is designed to mimic Pandas but with GPU acceleration. I use the same group-by and sum operation as in the Pandas example, but now I expect it to run much faster since it’s leveraging my GPU for computation.
def cudf_operation():
gdf = cudf.read_csv('large_dataset.csv')
result_cudf = gdf.groupby('col3')['col2'].sum()
Running the Operations
Finally, I run both operations using my run_and_time function to capture how long each one takes. The goal here is to see how much faster cuDF is compared to Pandas.
pandas_time = run_and_time(pandas_operation, "Pandas operation")
cudf_time = run_and_time(cudf_operation, "cuDF operation")
Results:
Here is the complete code snippet:
import pandas as pd
import cudf
import time
import numpy as np
import matplotlib.pyplot as plt
# Generate dataset
data_size = 70000000
df = pd.DataFrame({
'col1': np.random.randn(data_size),
'col2': np.random.randint(0, 100, size=data_size),
'col3': np.random.choice(['A', 'B', 'C', 'D'], size=data_size)
})
df.to_csv('large_dataset.csv', index=False)
# Function to run and time an operation
def run_and_time(func, operation_name):
print(f"Starting {operation_name}...")
start_time = time.time()
func()
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{operation_name} completed in {elapsed_time:.2f} seconds.")
return elapsed_time
# Define the pandas operation
def pandas_operation():
df = pd.read_csv('large_dataset.csv')
result_pandas = df.groupby('col3')['col2'].sum()
# Define the cuDF operation
def cudf_operation():
gdf = cudf.read_csv('large_dataset.csv')
result_cudf = gdf.groupby('col3')['col2'].sum()
# Run both operations and time them
pandas_time = run_and_time(pandas_operation, "Pandas operation")
cudf_time = run_and_time(cudf_operation, "cuDF operation")
# Visualization: Mimic progress bars as a static chart
fig, ax = plt.subplots(figsize=(10, 3))
# Create the bars for pandas and cuDF
ax.barh(['pandas'], [pandas_percentage], color='blue', edgecolor='black', height=0.4)
ax.barh(['cuDF'], [cudf_percentage], color='orange', edgecolor='black', height=0.4)
# Set the x-axis limit from 0 to 100 to mimic percentage
ax.set_xlim(0, 100)
# Add grid lines to mimic terminal progress bar style
ax.xaxis.grid(True, color='gray', linestyle='--', linewidth=0.5)
ax.set_axisbelow(True)
# Hide unnecessary ticks and spines
ax.tick_params(left=False, bottom=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
# Add text to show percentage values and processing times on the bars
ax.text(pandas_percentage + 1, 0, f'{pandas_time:.4f} s', va='center', ha='left', color='black', fontsize=10)
ax.text(cudf_percentage + 1, 1, f'{cudf_time:.4f} s', va='center', ha='left', color='black', fontsize=10)
# Set titles and labels
ax.set_xlabel('Processing Time', fontsize=12)
ax.set_title('Comparison: pandas vs cuDF', fontsize=14)
plt.tight_layout()
plt.show()
More detailed benchmark: performance-comparisons.ipynb
cuDF pandas documentation: cuDF Pandas
For any questions and consultation, reach out at nurbol.sakenov@outlook.com


